Dynamic segmentation

The Dynamic segmentation pattern is useful to perform the classification of entities based on measures. A typical example is to cluster customers based on spending volume. The clustering is dynamic, so that the categorization considers the filters active in the report. Indeed, a customer might belong to different clusters on different dates.
Basic pattern
You need to categorize customers based on spending. Using a configuration table like Figure 1, you define the clusters.
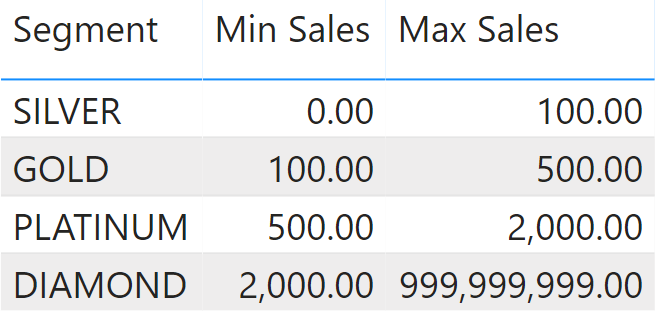
Every segment represents a classification for a customer based on their Sales Amount computed over one year. Using this configuration, you want to analyze how many customers belong to each segment over time. One same customer might be Silver in one year, and Platinum in a different year.
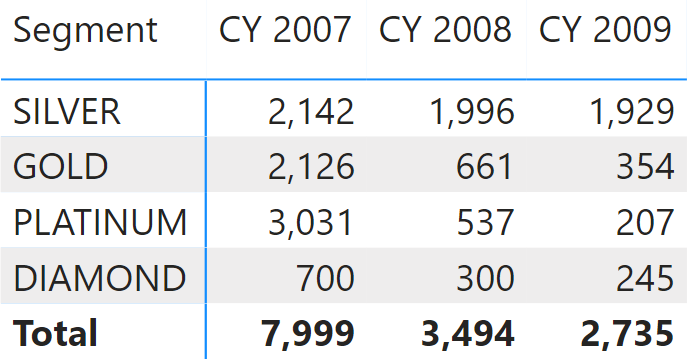
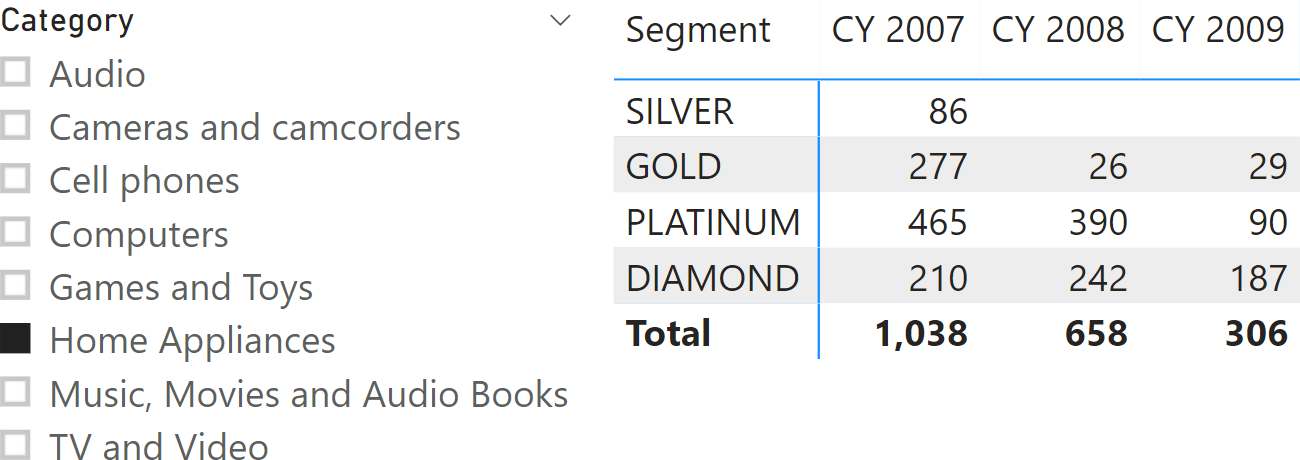
In the report in Figure 2, the first row shows that in 2007 there were 2,142 customers in the SILVER segment. By adding a Category slicer to this report, we segment our customers based on their purchases in the chosen category alone, as shown in Figure 3.
Being dynamic, the pattern is implemented through a measure. The measure finds the customers who belong to the selected cluster. It then uses this table as a filter in CALCULATE to restrict the calculation to the customers found. KEEPFILTERS is needed to intersect the customers list with the customers found:
# Seg. Customers :=
IF (
HASONEVALUE ( 'Date'[Calendar Year] ), -- Segmentation only over one year selected
VAR CustomersInSegment = -- Gets the customers in the current segment
FILTER (
ALLSELECTED ( Customer ),
VAR SalesOfCustomer = [Sales Amount] -- Computes Sales Amount for one customer
VAR SegmentForCustomer = -- Retrieves the segment
FILTER ( -- a customer belongs to
'Customer segments',
NOT ISBLANK ( SalesOfCustomer )
&& 'Customer segments'[Min Sales] < SalesOfCustomer
&& 'Customer segments'[Max Sales] >= SalesOfCustomer
)
VAR IsCustomerInSegments = NOT ISEMPTY ( SegmentForCustomer )
RETURN IsCustomerInSegments
)
VAR Result =
CALCULATE (
COUNTROWS ( Customer ), -- Expression to compute
KEEPFILTERS ( CustomersInSegment ) -- Applies filter for segmented customers
)
RETURN Result
)
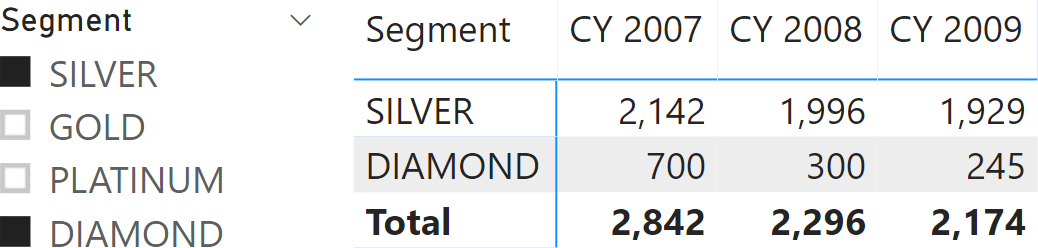
The measure must iterate through all the segments for each customer, to make sure the total is correct with an arbitrary selection of segments, as shown in Figure 4.
By nature, this calculation is non-additive. The previous implementation works at the year level only, which is a good idea to compute the number of customers. This way, the same customer is never summed twice. However, for other measures the segmentation could require an additive behavior. For example, imagine a measure showing the Sales Amount of the customer in the segment that should also show a total over multiple years. The following measure implements a calculation that is additive across the years:
Sales Seg. Customers :=
SUMX (
VALUES ( 'Date'[Calendar Year] ), -- Repeat segmentation for every year selected
VAR CustomersInSegment = -- Gets the customers in the current segment
FILTER (
ALLSELECTED ( Customer ),
VAR SalesOfCustomer = [Sales Amount] -- Computes Sales Amount for one customer
VAR SegmentForCustomer = -- Retrieves the segment
FILTER ( -- a customer belongs to
'Customer segments',
NOT ISBLANK ( SalesOfCustomer )
&& 'Customer segments'[Min Sales] < SalesOfCustomer
&& 'Customer segments'[Max Sales] >= SalesOfCustomer
)
VAR IsCustomerInSegments = NOT ISEMPTY ( SegmentForCustomer )
RETURN IsCustomerInSegments
)
VAR Result =
CALCULATE (
[Sales Amount], -- Expression to compute
KEEPFILTERS ( CustomersInSegment ) -- Applies filter for segmented customers
)
RETURN Result
)
The result shown in Figure 5 provides a total in each row, summing the measure computed for each year.

You need to make sure that the configuration table is designed properly, so that each possible value of Sales Amount only belongs to one segment. The presence of overlapping segment boundaries in the configuration table can generate errors in the evaluation of the CustomersInSegment variable. If you want to make sure there are no mistakes in the configuration table – such as overlapping ranges – you can generate the Max Sales column using a calculated column that retrieves the value of Min Sales for the next segment. This is shown in the following sample code:
Max Sales Calculated =
VAR CurrentMinSales = 'Customer Segments'[Min Sales]
VAR MaxEverSales = CALCULATE ( [Sales Amount], REMOVEFILTERS ( ) )
VAR NextMinSales =
CALCULATE (
MIN ( 'Customer Segments'[Min Sales] ),
REMOVEFILTERS ( 'Customer Segments' ),
'Customer Segments'[Min Sales] > CurrentMinSales
)
VAR MaxSales =
IF ( ISBLANK ( NextMinSales ), MaxEverSales, NextMinSales )
RETURN
MaxSales
Clustering by product growth
The dynamic segmentation pattern is very flexible, because it allows you to categorize entities based on dynamic calculations. Moreover, one entity might belong to different clusters. A good example of its flexibility is the following: you want to cluster products based on their yearly growth in sales.
In the sample model, if the year-over-year growth of a product falls within the +/-20% range, then it is considered stable; if its growth is lower than -20%, then it is dropping; if it is over 20%, then it is growing. The same product might be dropping in 2008 and stable in 2009, as highlighted in Figure 6.
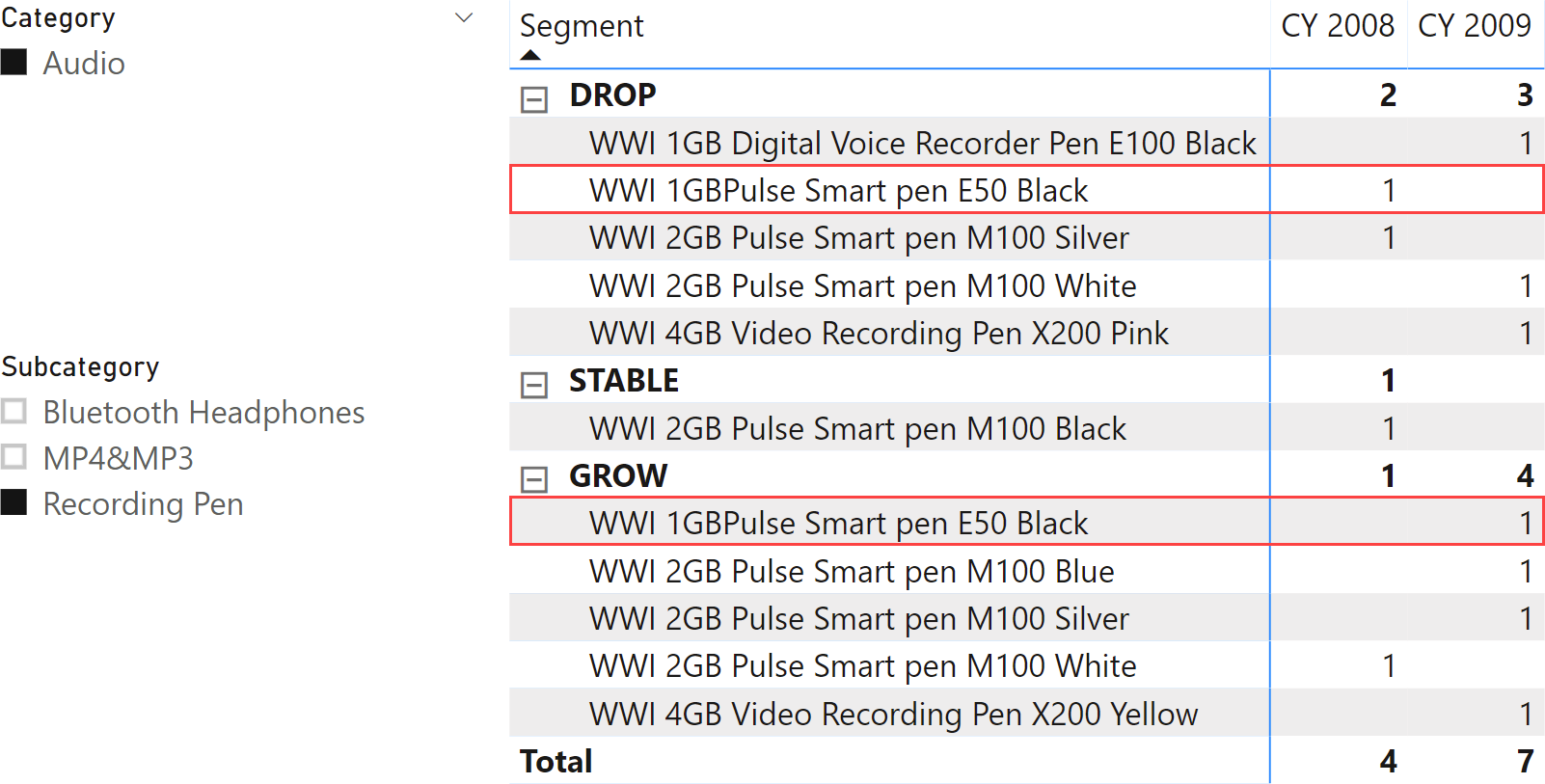
You start by building the segmentation table. It is shown in Figure 7.
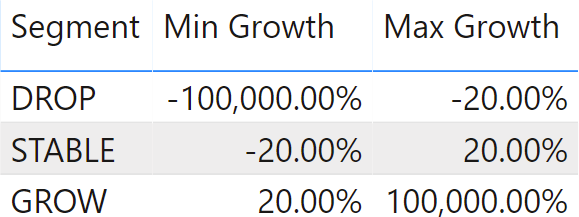
Once the table is in the model, the code to use is a slight variation of the basic model. This time, instead of determining the customers who belong to a segment based on their spending volume, it determines the products that belong to a segment based on product growth. The only difference in the measure is the reference to the Growth % measure:
Growth % :=
VAR SalesCY = [Sales Amount]
VAR SalesPY =
CALCULATE (
[Sales Amount],
SAMEPERIODLASTYEAR ( 'Date'[Date] )
)
VAR Result =
IF (
NOT ISBLANK ( SalesCY ) && NOT ISBLANK ( SalesPY ),
DIVIDE ( SalesCY - SalesPY, SalesPY )
)
RETURN
Result
# Seg. Products :=
IF (
HASONEVALUE ( 'Date'[Calendar Year] ),
VAR ProductsInSegment = -- Gets the customers in the current segment
FILTER (
ALLSELECTED ( 'Product' ),
VAR GrowthPerc = [Growth %] -- Computes Growth% for one product
VAR SegmentForProduct = -- Retrieves the segment a customer belongs to
FILTER (
'Growth segments',
NOT ISBLANK ( GrowthPerc )
&& 'Growth segments'[Min Growth] < GrowthPerc
&& 'Growth segments'[Max Growth] >= GrowthPerc
)
VAR IsProductInSegments = NOT ISEMPTY ( SegmentForProduct )
RETURN IsProductInSegments
)
VAR Result =
CALCULATE (
COUNTROWS ( 'Product' ), -- Expression to compute
KEEPFILTERS ( ProductsInSegment ) -- Applies filter for segmented products
)
RETURN Result
)
Clustering by best status
The dynamic segmentation pattern is also useful to cluster customers based on sales, assigning each customer to exactly one cluster depending on the highest sales for that customer over time.
If the assignment of the cluster to each customer is static, then this is better implemented through the static segmentation pattern. However, if the assignment has to be dynamic but you do not want a customer to belong to different clusters over time, then the dynamic segmentation pattern is the optimal choice.
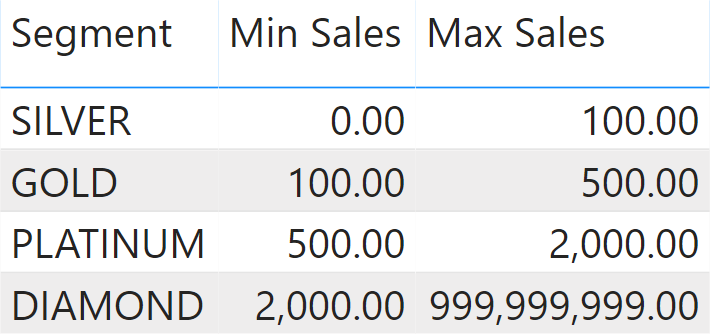
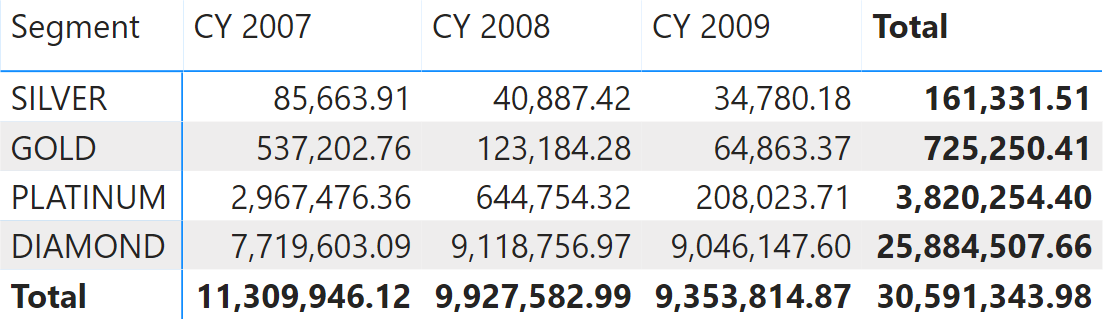
Starting with the configuration table in Figure 8, we assign customers to one cluster depending on the highest yearly sales. Therefore, a customer is PLATINUM if – in a year – they exceeded the amount of 500.00 spent. If it is determined that the customer be platinum, their sales are reported under the PLATINUM segment for all the years.
In the report shown in Figure 9, the sales reported under PLATINUM are the sales of all customers that reached the platinum level in one of the selected years. If their sales are reported under PLATINUM, they are not reported in any other cluster.
The measure in the report is a variation of the dynamic segmentation pattern. This time it is not necessary to iterate the calculation over the years. The CustomersInSegment variable computes the max sales amount for each year in the report using the Max Yearly Sales measure, which also ignores any other filter over the Date table. The result is applied as a filter to compute the Sales Amount measure:
Max Yearly Sales :=
MAXX (
ALLSELECTED ( 'Date'[Calendar Year] ), -- Iterates over selected years
CALCULATE (
[Sales Amount], -- Computes the Sales Amount of the year
ALLEXCEPT ( -- ignoring any other filter
'Date', -- applied to the Date table other than
'Date'[Calendar Year] -- the one coming from context transition
)
)
)
Sales Seg. Customers :=
VAR CustomersInSegment = -- Gets the customers in current segment
FILTER (
ALLSELECTED ( Customer ),
VAR SalesOfCustomer = [Max Yearly Sales] -- Computes Sales Amount for one customer
VAR SegmentForCustomer = -- Retrieves the segment
FILTER ( -- a customer belongs to
'Customer segments',
NOT ISBLANK ( SalesOfCustomer )
&& 'Customer segments'[Min Sales] < SalesOfCustomer
&& 'Customer segments'[Max Sales] >= SalesOfCustomer
)
VAR IsCustomerInSegments = NOT ISEMPTY ( SegmentForCustomer )
RETURN IsCustomerInSegments
)
VAR Result =
CALCULATE (
[Sales Amount], -- Expression to compute
KEEPFILTERS ( CustomersInSegment ) -- Applies filter for segmented customers
)
RETURN
Result
Evaluates an expression in a context modified by filters.
CALCULATE ( <Expression> [, <Filter> [, <Filter> [, … ] ] ] )
Changes the CALCULATE and CALCULATETABLE function filtering semantics.
KEEPFILTERS ( <Expression> )
This pattern is designed for Power BI / Excel 2016-2019. An alternative version for Excel 2010-2013 is also available.
This pattern is included in the book DAX Patterns, Second Edition.


Video

Do you prefer a video?
This pattern is also available in video format. Take a peek at the preview, then unlock access to the full-length video on SQLBI.com.Watch the full video — 20 min.
Downloads
Download the sample files for Power BI / Excel 2016-2019: