Related distinct count

The Related distinct count pattern is useful whenever you have one or more fact tables related to a dimension, and you need to perform the distinct count of column values in a dimension table only considering items related to transactions in the fact table. For demonstration purposes we use the distinct count of the product name in a model with two fact tables: Sales and Receipts.
Because the product name is not unique – we artificially introduced duplicated names by removing the color description from the product name – a simple distinct count of the product key in the Sales or Receipts table does not work. Finally, we show how to compute the distinct count of product names that appear in both tables and in at least one of the two.
Pattern description
The Product[Product Name] column is not unique in the Product table and we need the distinct count of the product names that have related sales transactions. The model contains two tables with transactions related to products: Sales and Receipts. Figure 1 shows this data model.
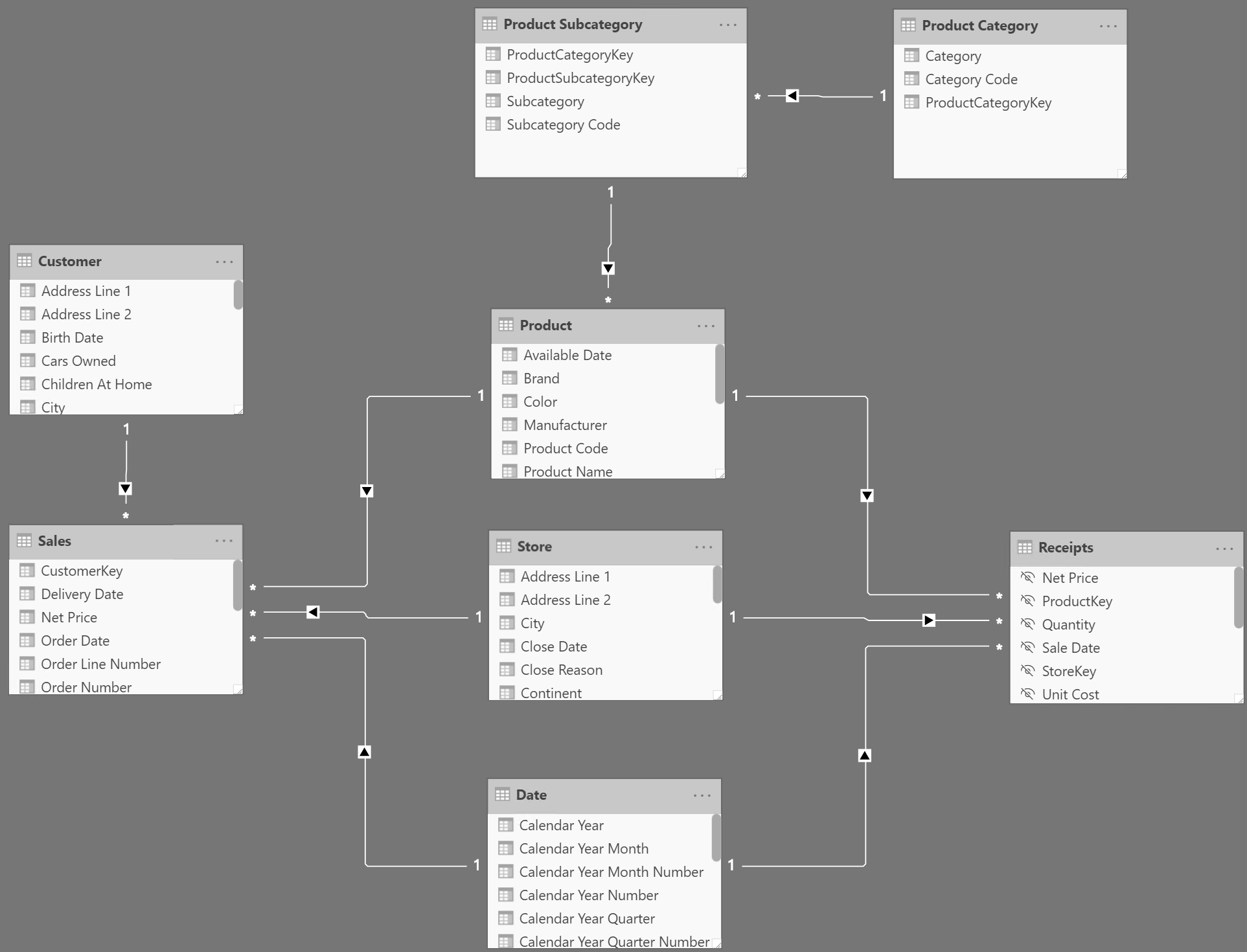
Based on this model we want to compute the distinct count of product names appearing:
- In Sales.
- In Receipts.
- In both the Sales and Receipts
- In at least one of the Sales and Receipts
The report is visible in Figure 2.
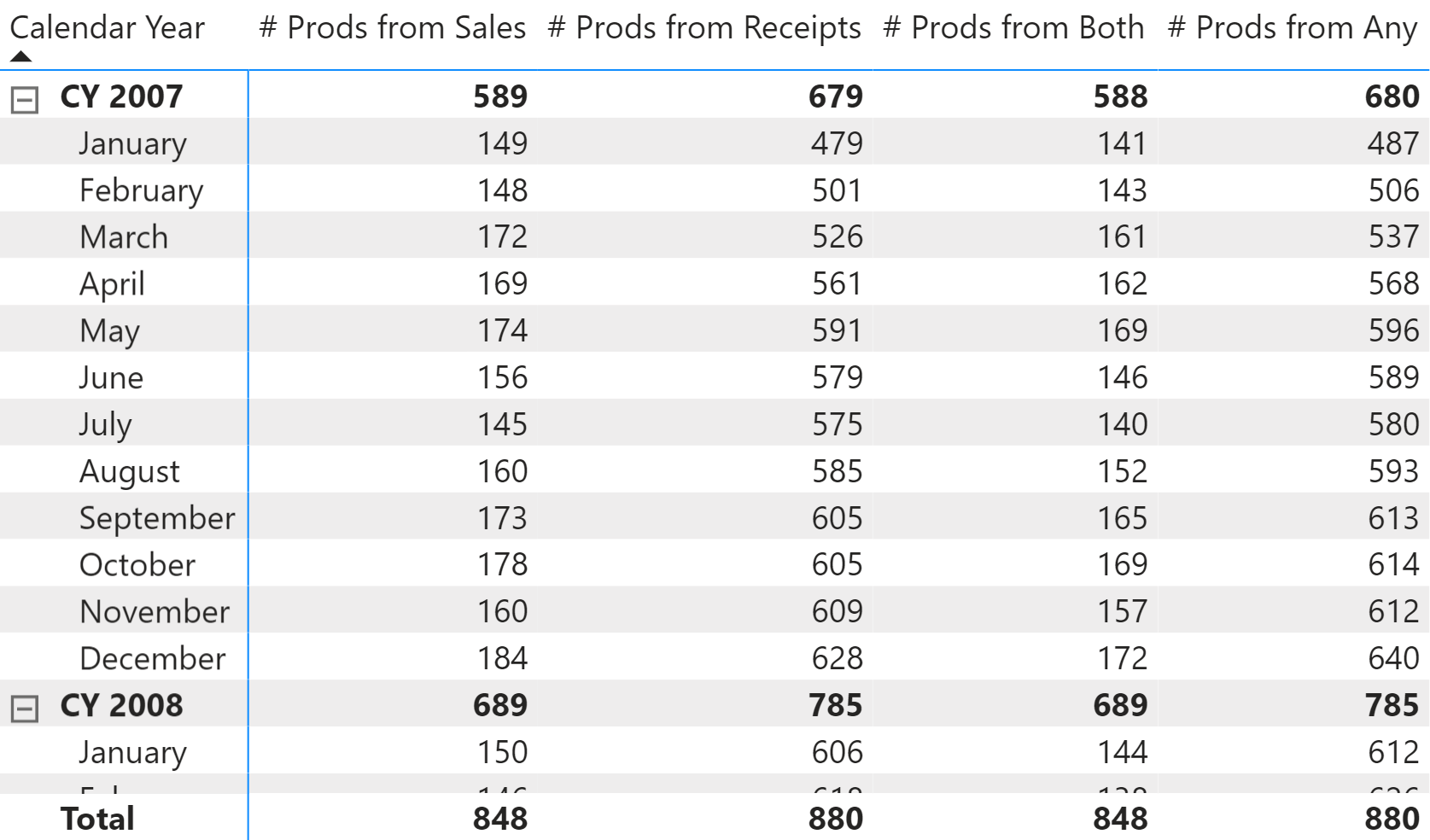
The code for the first two measures is the following:
# Prods from Sales :=
VAR ProdsFromSales =
SUMMARIZE ( Sales, 'Product'[Product Name] )
VAR Result =
SUMX ( ProdsFromSales, 1 ) -- optimization for COUNTROWS ( ProdsFromSales )
RETURN
Result
# Prods from Receipts :=
VAR ProdsFromReceipts =
SUMMARIZE ( Receipts, 'Product'[Product Name] )
VAR Result =
SUMX ( ProdsFromReceipts, 1 ) -- optimization for COUNTROWS ( ProdsFromReceipts )
RETURN
Result
Using SUMMARIZE, the # Prods from Sales and # Prods from Receipts measures retrieve the distinct product names referenced in the relevant table. SUMX just counts the number of those products and it is used instead of COUNTROWS or DISTINCTCOUNT for performance reasons – more details in the article Analyzying the performance of DISTINCTCOUNT in DAX.
Despite being longer than a solution using DISTINCTCOUNT and bidirectional cross-filtering, this version of the code is faster in the most frequent case – where the number of products is significantly smaller than the number of transactions.
NOTE The natural syntax to compute the Result variable in the # Prods from Sales and # Prods from Receipts measures should use COUNTROWS. The SUMX version is only suggested for performance reasons in the simple measures. The following measures of this pattern use COUNTROWS because there would be no advantage in using SUMX in more complex expressions.
The formulation using SUMMARIZE and COUNTROWS can be easily extended to accommodate for the next formulas that produce the intersection (# Prods from Both) or the union (# Prods from Any) of the product names:
# Prods from Both :=
VAR ProdsFromSales =
SUMMARIZE ( Sales, 'Product'[Product Name] )
VAR ProdsFromReceipts =
SUMMARIZE ( Receipts, 'Product'[Product Name] )
VAR ProdsFromBoth =
INTERSECT ( ProdsFromSales, ProdsFromReceipts )
VAR Result =
COUNTROWS ( ProdsFromBoth )
RETURN
Result
# Prods from Any :=
VAR ProdsFromSales =
SUMMARIZE ( Sales, 'Product'[Product Name] )
VAR ProdsFromReceipts =
SUMMARIZE ( Receipts, 'Product'[Product Name] )
VAR ProdsFromOne =
DISTINCT ( UNION ( ProdsFromSales, ProdsFromReceipts ) )
VAR Result =
COUNTROWS ( ProdsFromOne )
RETURN
Result
We provided the examples for INTERSECT and UNION. But the pattern can easily be adapted to perform more complex calculations. As a further example, the # Prods in Sales and not in Receipts measure computes the number of product names that exist in Sales but not in Receipts by using the set function EXCEPT instead of the INTERSECT or UNION functions used in previous measures:
# Prods in Sales and not in Receipts :=
VAR ProdsFromSales =
SUMMARIZE ( Sales, 'Product'[Product Name] )
VAR ProdsFromReceipts =
SUMMARIZE ( Receipts, 'Product'[Product Name] )
VAR ProdsFromSalesAndNotReceipts =
EXCEPT ( ProdsFromSales, ProdsFromReceipts )
VAR Result =
COUNTROWS ( ProdsFromSalesAndNotReceipts )
RETURN
Result
The result of the # Prods in Sales and not in Receipts measure is visible in Figure 3.
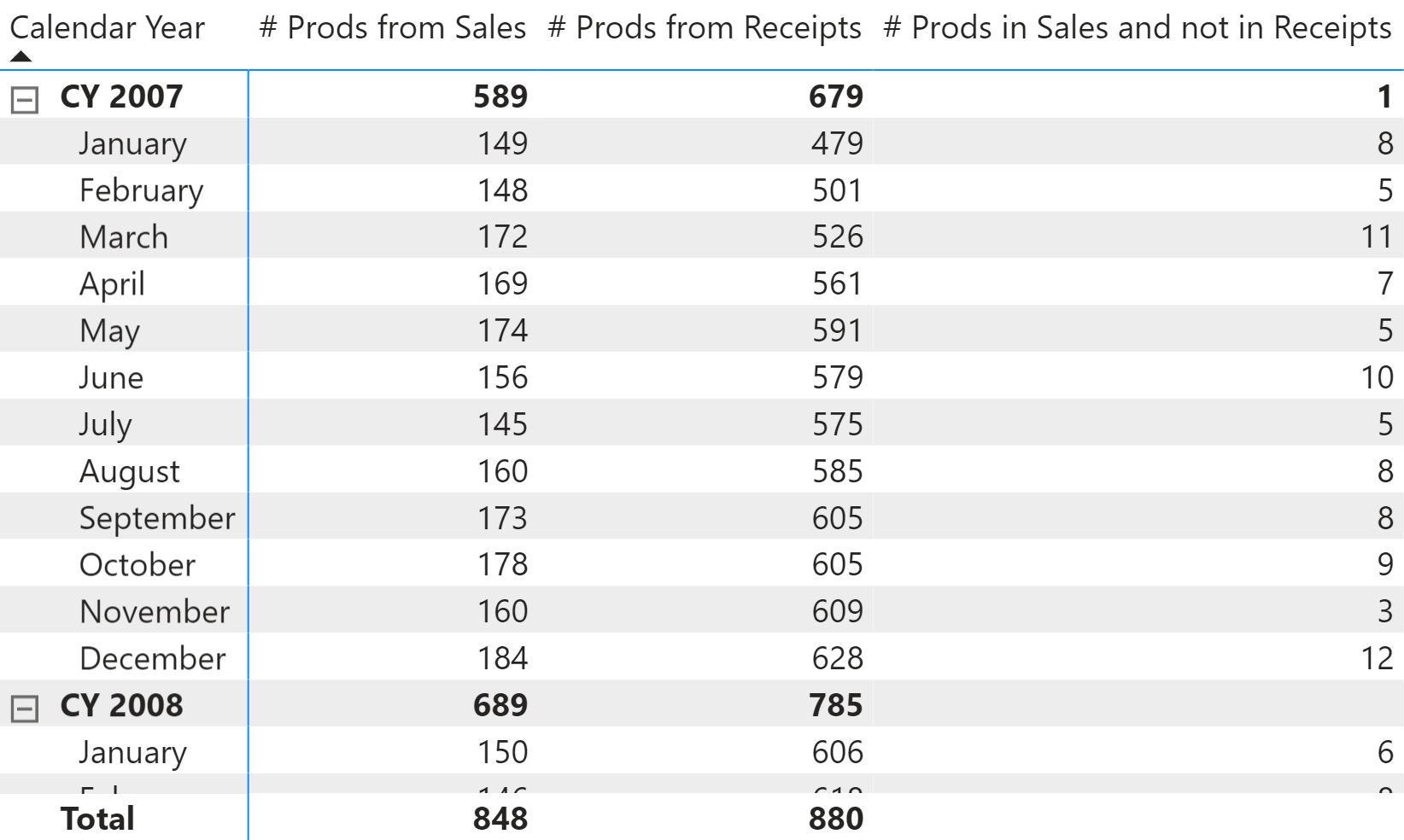
The pattern can be extended to compute the distinct count of any column in a table that can be reached through a many-to-one chain of relationships from the fact tables. This is because SUMMARIZE is able to group by any of those columns.
Creates a summary of the input table grouped by the specified columns.
SUMMARIZE ( <Table> [, <GroupBy_ColumnName> [, [<Name>] [, [<Expression>] [, <GroupBy_ColumnName> [, [<Name>] [, [<Expression>] [, … ] ] ] ] ] ] ] )
Returns the sum of an expression evaluated for each row in a table.
SUMX ( <Table>, <Expression> )
Counts the number of rows in a table.
COUNTROWS ( [<Table>] )
Counts the number of distinct values in a column.
DISTINCTCOUNT ( <ColumnName> )
Returns the rows of left-side table which appear in right-side table.
INTERSECT ( <LeftTable>, <RightTable> )
Returns the union of the tables whose columns match.
UNION ( <Table>, <Table> [, <Table> [, … ] ] )
Returns the rows of left-side table which do not appear in right-side table.
EXCEPT ( <LeftTable>, <RightTable> )
This pattern is designed for Power BI / Excel 2016-2019. An alternative version for Excel 2010-2013 is also available.
This pattern is included in the book DAX Patterns, Second Edition.


Video

Do you prefer a video?
This pattern is also available in video format. Take a peek at the preview, then unlock access to the full-length video on SQLBI.com.Watch the full video — 12 min.
Downloads
Download the sample files for Power BI / Excel 2016-2019: